
Stock Headline Sentiment Accuracy Classifier
- Category: ML Model
- Client: Durham University
- Project date: May 2021
Summary
An investigation into how accurate the sentiment of stock news headlines are, compare to the stock's real-world performance. Implemented using Python, SKLearn, Pandas and Requests.
STAR Breakdown
- Situation: With the record numbers of new investors, I was interested to examine how accurately the sentiments of analyst reports for specific stocks represented their performance.
- Task: To examine the accuracy of stock article headlines’ sentiments, I would first need to categorize a dataset of headlines through natural-language processing. Then, I would need to access a dataset of stock performances for the relevant stocks and compare the results over varying timeframes.
- Action: Firstly, I explored a Kaggle dataset of millions of headlines, labelled with relevant stock trackers and performed some prep on the data to ensure it’s quality. I then accessed the Marketstack API and automatically gathered the price data for the last decade for all 100 stocks. I then compared the sentiments with price change over time, before training a support vector machine on the labelled headlines to examine if consistent trends in inaccurate headlines could be examined.
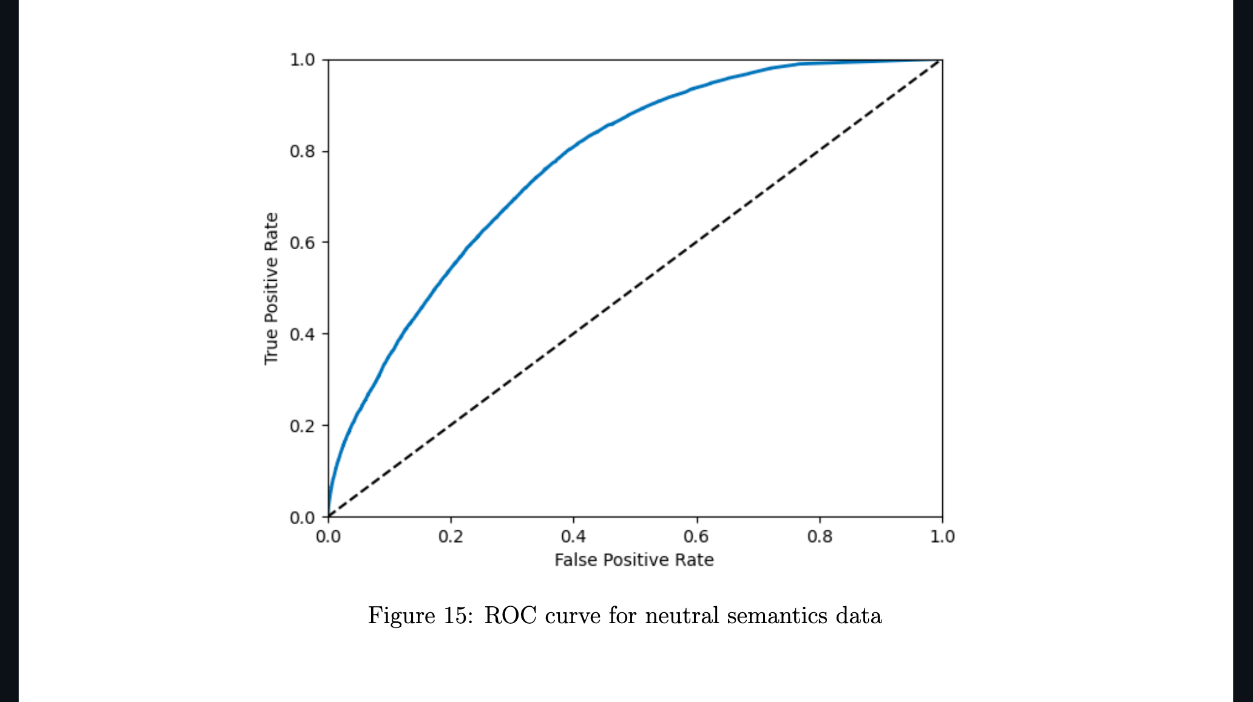
- Result: Of the two models created, both displayed better-than-random classifications of headlines as having correct or incorrect sentiment. Such a result indicates a relationship between headline language and sentiment accuracy, something I wish to explore further.